Lessons from the Microsoft 365 and AWS Outages: Why Single-Vendor Cloud Risk Matter
30/10/2025 – Jon Pertwee
This month’s twin cloud failures are a reminder of how fragile our digital ecosystem really is. On 20 October 2025, Amazon Web Services (AWS) suffered a major disruption rooted in a DNS fault. Just nine days later, on 29 October, Microsoft Azure and Microsoft 365 experienced a global outage triggered by a configuration error in their DNS and edge delivery infrastructure.
Both events stemmed from the same weak link: the Domain Name System (DNS): the digital equivalent of a phonebook for the internet. The result? Widespread disruption across businesses, governments and consumer services worldwide.
What Happened
AWS (20 Oct):
A DNS resolution issue in the US-East-1 region cascaded across AWS services. Popular applications such as Amazon, Alexa, Snapchat and Fortnite went offline before service was restored 15-16 hours later.
Microsoft (29 Oct):
A configuration change to Azure Front Door, Microsoft’s global delivery network, caused DNS and routing failures. This disrupted Microsoft 365, Xbox Live, and affected brands including Starbucks and multiple airlines for 8-10 hours.
A Shared Weakness
Both incidents underline the same uncomfortable truth: a small number of cloud providers now underpin most of the internet. When one control plane falters, thousands of services fail together.
DNS may seem mundane, but when it fails, so does everything built upon it. The week’s outages exposed just how thin global resilience has become.
Why “All Eggs in One Basket” No Longer Works
-
Correlated risk: Shared infrastructure means shared failure modes.
-
Attractive targets: Centralisation makes hyperscale platforms appealing to attackers.
-
Hidden dependencies: Many “independent” systems rely on the same cloud regions, DNS networks, or routing paths.
Building Real Resilience
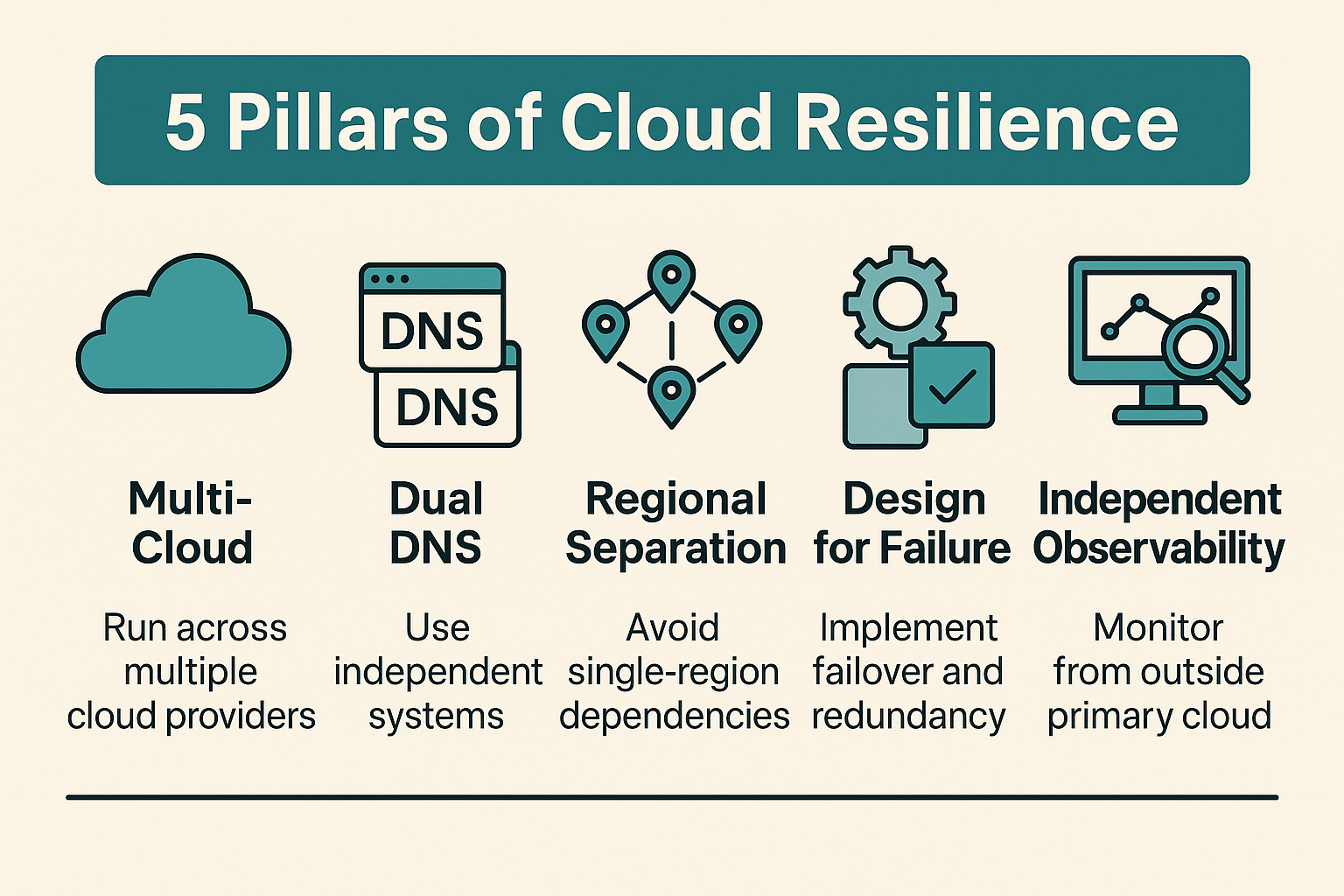
If your organisation cannot tolerate extended downtime, diversification is essential, both technically and operationally.
-
Adopt multi-cloud selectively: Run critical services across two providers or regions, with automated, AND TESTED failover.
-
Use dual DNS providers: Separate DNS providers with health checks and controlled TTLs to improve reliability.
-
Plan for regional separation: Avoid hard dependencies on a single region (notably us-east-1, which has historically experienced multiple outages).
-
Design for graceful degradation: Implement caching, circuit breakers, and queued operations to sustain core functionality when dependencies fail.
-
Independent observability: Use third-party monitoring to detect and respond faster than provider dashboards alone.
The Business Case for Diversification
Multi-cloud is not about chasing theoretical uptime; it is about business continuity and risk management.
-
Revenue protection: A few hours offline can cost more than a year of resilience investment.
-
Compliance: Regulators increasingly expect demonstrable operational resilience.
-
Negotiation leverage: True portability enhances your position with vendors.
What These Outages Teach Us
- Cloud concentration is efficient but brittle. The recent DNS failures at AWS and Microsoft prove that even the largest providers are not immune to systemic faults.
- Efficiency gained through consolidation is real, but fragility multiplies when everyone depends on the same systems
- If your organisation’s continuity depends on a single vendor, you are not managing risk; you are accepting it.
How I Can Help
If these events made you question your organisation’s resilience posture, you are not alone. Many businesses have limited visibility into how their cloud dependencies overlap, or how a single outage could cascade through operations.
Our services are designed to help you understand, quantify and reduce these risks:
1. Cloud Dependency Assessment
Map your services to cloud regions, providers and DNS systems. Identify hidden single points of failure and potential choke-points.
2. Resilience Architecture Review
Evaluate your current architecture for failover readiness, multi-region design, and DNS robustness. Receive actionable, risk-based recommendations.
3. Failover Readiness & Testing
Design and implement cross-cloud or multi-region failover strategies. Conduct controlled failover tests or tabletop exercises to validate resilience.
4. Governance & Vendor Risk Strategy
Build governance structures and dashboards to track vendor concentration, dependency trends, and resilience metrics.
Next Steps
Understanding your exposure is the first step toward resilience.
Contact me today to arrange a no-obligation consultation on how to assess your organisation’s cloud dependency and business continuity posture.