Lessons from the Microsoft 365 and AWS Outages: Why Single-Vendor Cloud Risk Matters
30/10/2025 – Jon Pertwee
October 2025 produced two significant cloud failures in the space of nine days, and the proximity was instructive. On 20 October, Amazon Web Services suffered a major disruption rooted in a DNS fault. On 29 October, Microsoft Azure and Microsoft 365 experienced a global outage triggered by a configuration error in their DNS and edge delivery infrastructure.
Both events stemmed from the same weak link: the Domain Name System, DNS, the mechanism that translates the domain names we type into the IP addresses systems use to route traffic. The result in both cases was widespread disruption across businesses, governments, and consumer services worldwide. The shared cause was not a coincidence. It was a structural vulnerability.
What Happened
AWS (20 Oct):
A DNS resolution issue in the US-East-1 region cascaded across AWS services. Applications including Amazon’s own retail platform, Alexa, Snapchat, and Fortnite went offline. Service was restored approximately 15–16 hours later.
Microsoft (29 Oct):
A configuration change to Azure Front Door, Microsoft’s global content delivery and routing network, caused DNS and routing failures affecting Microsoft 365, Xbox Live, and downstream services used by organisations including Starbucks and several major airlines. The outage lasted approximately 8–10 hours.
A Shared Weakness
Both incidents point to the same uncomfortable structural reality: a small number of cloud providers now underpin most of the internet. When one control plane falters, thousands of services fail together, not because they are architecturally connected, but because they share a common dependency they may not even be aware of.
DNS is easy to overlook precisely because it is normally invisible. It works so reliably that organisations rarely think about what happens when it doesn’t. The answer, as October demonstrated twice, is that everything built on top of it stops working. Email, applications, authentication, monitoring, all of it depends on DNS resolution functioning correctly.
The week’s outages exposed how thin global resilience has become. Efficiency through consolidation is real, but fragility scales with it. When everyone depends on the same systems, failures are no longer isolated, they are correlated.
Why Concentration Creates Systemic Risk
-
- Correlated failure modes: Shared infrastructure means that a single fault; a configuration error, a DNS failure, a routing change, can simultaneously affect every organisation using that platform. Redundancy within a single provider does not protect against provider-level failures.
- Attractive targets: Hyperscale platforms are high-value targets for both technical failures and deliberate attack. The larger the platform, the more consequential a successful disruption.
- Hidden dependencies: Many services that appear independent share underlying cloud regions, DNS networks, or routing paths. An organisation may believe it has diversified when in practice two of its critical systems route through the same AWS region or use the same DNS provider.
Building Real Resilience
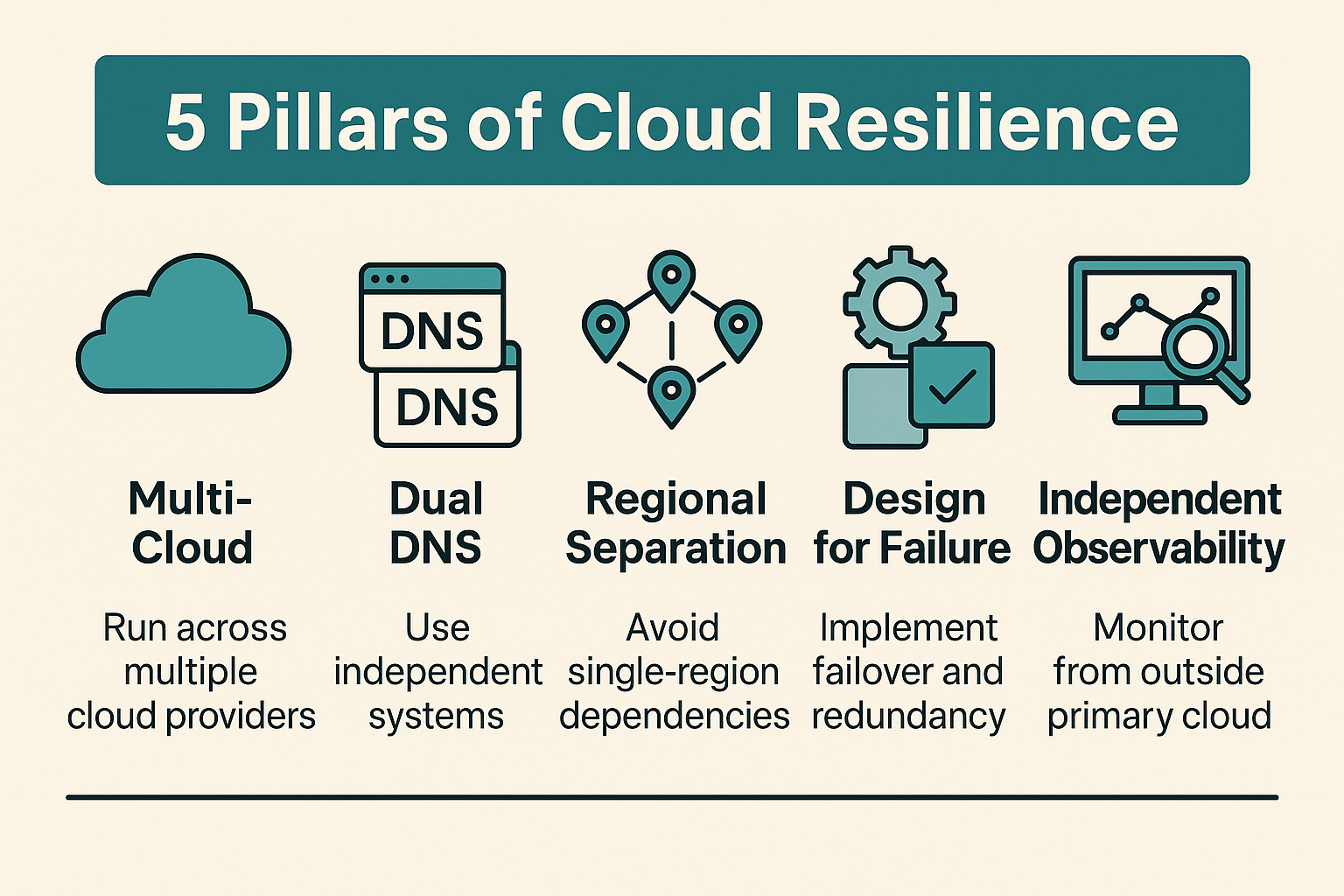
If your organisation cannot tolerate extended downtime, diversification is necessary — both technically and operationally. This does not mean abandoning a primary cloud provider. It means designing for the realistic failure modes that the primary provider cannot protect you against.
-
- Adopt multi-cloud selectively: Run critical services across two providers or regions, with automated and tested failover. Untested failover is not failover, it is a plan that has not yet been shown to work.
- Use dual DNS providers: Separate DNS providers with health checks and controlled TTLs significantly improve resilience to the failure mode that caused both October outages.
- Plan for regional separation: Avoid hard dependencies on a single region. US-East-1 in particular has a documented history of multiple significant outages.
- Design for graceful degradation: Implement caching, circuit breakers, and queued operations to sustain core functionality when dependencies fail. The goal is not perfect uptime, it is controlled, manageable degradation.
- Independent observability: Use third-party monitoring to detect failures and understand scope faster than provider status dashboards allow. In both October outages, organisations relying solely on provider dashboards had limited visibility during the early stages.
The Business Case for Diversification
Multi-cloud architecture is sometimes treated as a technical preference — something for organisations that have already solved their other problems. It is better understood as a risk management decision.
-
- Revenue protection: A few hours offline can cost more than a year of resilience investment. The calculation is straightforward once the cost of downtime is quantified.
- Regulatory compliance: Regulators in financial services, healthcare, and critical infrastructure increasingly expect demonstrable operational resilience. Concentration in a single provider is a risk that regulators are paying more attention to.
- Vendor leverage: Genuine portability changes the negotiating dynamic with cloud providers. Organisations that can credibly move workloads have more leverage on pricing, SLAs, and support.
What These Outages Teach Us
Cloud concentration is efficient but brittle. The October DNS failures at AWS and Microsoft demonstrated that even the largest, most capable providers are not immune to systemic faults, and that when such faults occur, the blast radius extends far beyond the provider’s own services.
The efficiency gains from consolidation are real. But fragility scales with concentration. If your organisation’s continuity depends on a single vendor, you are not managing risk, you are accepting it, often without fully accounting for what that acceptance means in practice.
Resilience is not about eliminating the possibility of failure. It is about ensuring that when failures occur, and they will, the impact is bounded, the response is prepared, and recovery is structured. That requires deliberate architectural choices made before the outage, not improvisation during it.
A Closing Note
Cloud dependency analysis and resilience architecture sit naturally within disaster recovery and business continuity planning. If the October outages raised questions about how your organisation’s cloud dependencies are mapped, or whether your recovery plans account for provider-level failures, that is a conversation worth having. Feel free to get in touch.